We present
Ctrl-X, a simple
training-free and
guidance-free framework for text-to-image (T2I) generation with structure and appearance control. Given user-provided structure and appearance images, Ctrl-X designs feedforward structure control to enable structure alignment with the structure image and semantic-aware appearance transfer to facilitate the appearance transfer from the appearance image. Ctrl-X supports novel structure control with arbitrary condition images of any modality, is significantly faster than prior training-free appearance transfer methods, and provides instant plug-and-play to any T2I and text-to-video (T2V) diffusion model.
How does it work? Given clean structure and appearance latents, we first obtain noised structure and appearance latents via the diffusion forward process, then extracting their U-Net features from a pretrained T2I diffusion model. When denoising the output latent, we inject convolution and self-attention features from the structure latent and leverage self-attention correspondence to transfer spatially-aware appearance statistics from the appearance latent to achieve structure and appearance control. We name our method "Ctrl-X" because we reformulate the controllable generation problem by 'cutting' (and 'pasting') structure preservation and semantic-aware stylization together.

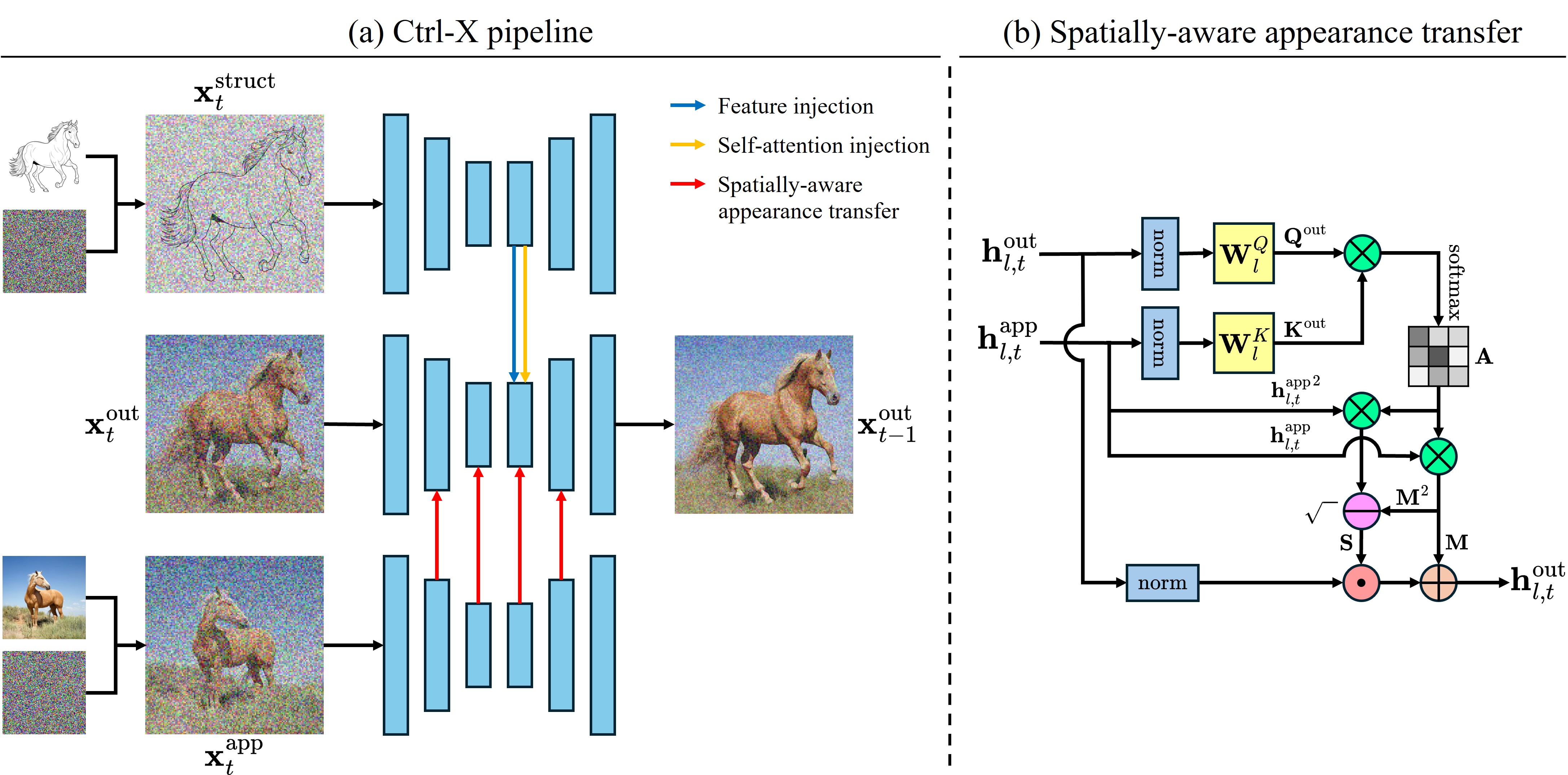







Comment: Training-free conditional generation by guidance in diffusion U-Net subspaces for structure control and appearance regularization.