
FreeControl: Training-Free Spatial Control of Any Text-to-Image Diffusion Model with Any Condition
1 UCLA,
2 University of Wisconsin-Madison,
3 Innopeak Technology, Inc
* Equal contribution
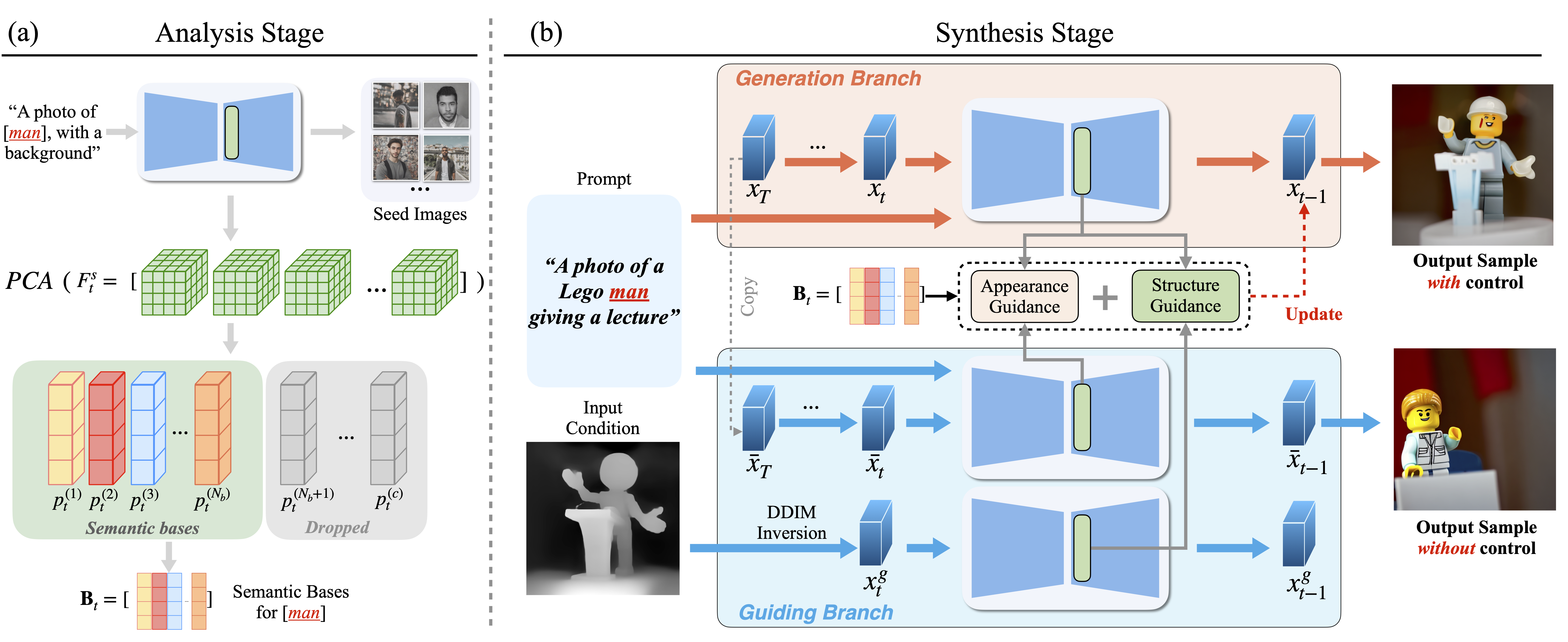 |
 |
 |
@article{mo2023freecontrol,
title={FreeControl: Training-Free Spatial Control of Any Text-to-Image Diffusion Model with Any Condition},
author={Mo, Sicheng and Mu, Fangzhou and Lin, Kuan Heng and Liu, Yanli and Guan, Bochen and Li, Yin and Zhou, Bolei},
journal={arXiv preprint arXiv:2312.07536},
year={2023}
}

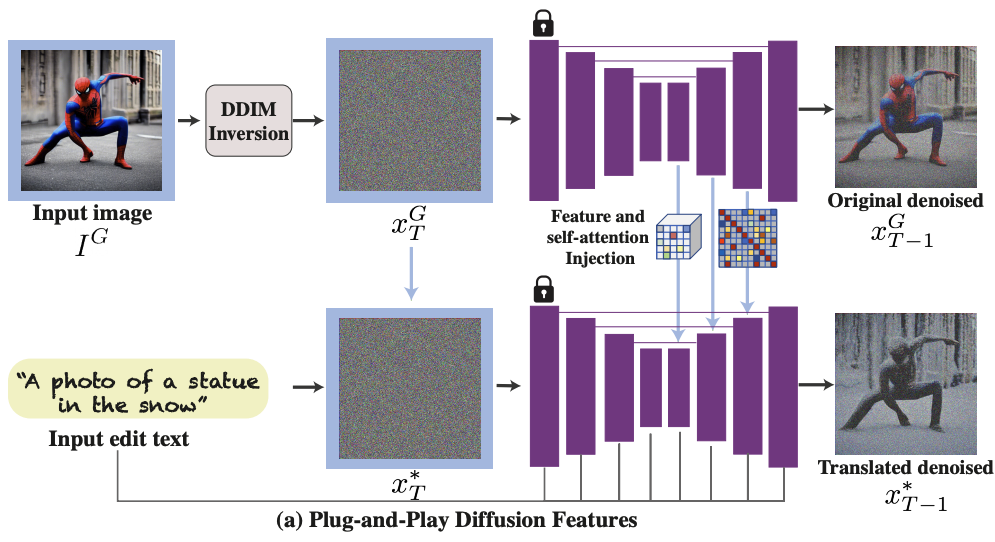

Comment: Builds a addition encoder to add spatial conditioning controls to T2I diffusion models.